Internettet er ved et tip. Den fortsatte stigning i adblocking har bragt en stopper for indtægtsmodellen, der udelukkende er afhængig af annonce dollars til at drive websteder og virksomheder.
Især nyhedswebsteder er begyndt at eksperimentere med måder at diversificere indkomstkilder på, og en fremtrædende mulighed, som websteder som The Wall Street Journal, Financial Times, The New York Times eller The Washington Post alt sammen har implementeret, er paywall-systemet.
Der er forskellige typer af betalingsvægge, men de har alle det til fælles, at de blokerer adgangen til indhold enten direkte eller efter at et vist antal artikler er blevet læst på webstedet.
Besøgende bliver derefter bedt om at abonnere på webstedet for at fortsætte med at læse artikler om det.
Det kan være fornuftigt ud fra et forretningsmæssigt synspunkt og kan være mere lukrativt end at kæmpe for det med brugere, der kører adblockere, men der er en ulempe med det både for det betalingsmåls websted og den blokerede bruger.
Websteder mister en høj procentdel af besøgende, hvis de implementerer et paywall-system. Det er uklart, hvor høj procentdelen virkelig er, og den varierer sandsynligvis fra sted til sted, men det er sandsynligvis meget højere end procentdelen af besøgende, der abonnerer på webstedet efter at have fået valget om at abonnere for at læse den ønskede artikel.
Maskerer din browser
Det er ingen hemmelighed, at nyhedswebsteder giver adgang til nyhedsaggregatorer og søgemaskiner. Hvis du f.eks. Tjekker Google Nyheder eller Søg, finder du artikler fra websteder med betalingsmurer, der er anført der.
Tidligere har nyhedswebsteder tilladt adgang til besøgende fra større nyhedsaggregatorer som Reddit, Digg eller Slashdot, men denne praksis ser ud til at være så god som død i dag.
Et andet trick, at indsætte artikeltitlen i en søgemaskine for at læse den cachelagrede historie på den direkte, ser ikke ud til at fungere ordentligt, ligesom artikler på websteder med betalingsvægge normalt ikke cache.
Opdatering : Wall Street Journal meddelte, at det vil tilslutte hullet beskrevet nedenfor. Du kan stadig læse artikler bag webstedets betalingsmur dog ved hjælp af følgende metode:
- Tryk på F12, når du er på artikelsiden med den afskårne artikel, og anmodningen om at abonnere for at læse den fuldt ud.
- Åbn konsolfanen.
- Indsæt javascript: windows.location = "// m.facebook.com/l.php?u="+encodeURIComponent(window.location.href);
- Hit enter.
Siden skal genindlæses, og artiklen skal indlæses fuldt ud. Du kan også sende artiklelinket på Facebook, for eksempel i et nyt indlæg, som kun du kan se. Klik på det udgivne link skal indlæse artiklen i sin helhed på webstedet Wall Street Journal.
Bruger-agent og henviser
Du undrer dig sandsynligvis over, hvordan websteder blokerer eller giver adgang til webstedets indhold. Metoderne er forbedret i årenes løb, og det er ikke længere nok blot at ændre browserens henvisning til //www.google.com/ for at få fuld adgang til et websteds indhold.
I stedet bruger websteder forskellige kontroller, der inkluderer brugeragent, henviser og cookies, og nogle gange endda mere end det, for at bestemme legitimiteten af adgangen.
Generel information
Sandsynligvis er den bedste måde at maskerer browseren på at gøre det tilsyneladende Googlebot.
- Henviser: //www.google.com/
- Brugeragent: Mozilla / 5.0 (kompatibel; Googlebot / 2.1; + // www.google.com/bot.html
Firefox
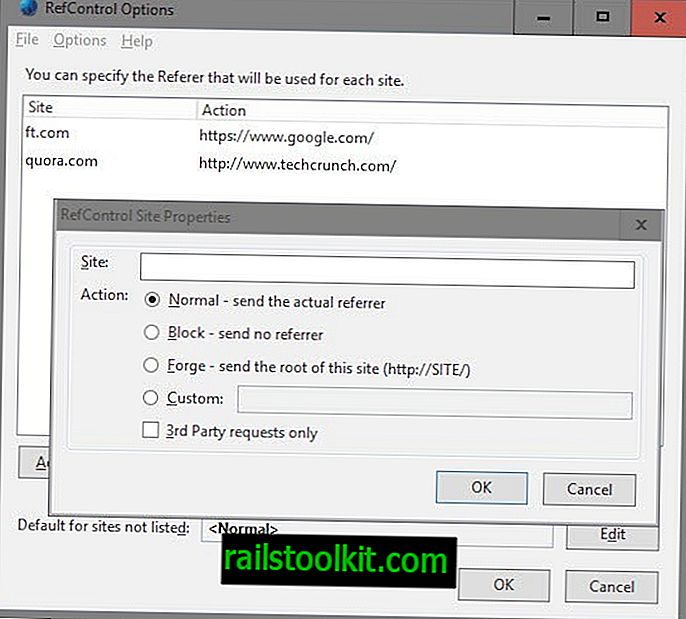
Firefox-brugere har brug for to browser-tilføjelser til det: den første, RefControl, for at ændre henvisningsværdien, når de besøger nyhedswebsteder, den anden, User Agent Switcher, for at ændre brugeragenten til browseren.
- Download og installer begge udvidelser i Firefox webbrowser.
- Tryk på Alt-tasten, og vælg Værktøjer> RefControl-indstillinger.
- Klik på "tilføj site", indtast et domænenavn under webstedet, vælg tilpasset handling, og indtast //www.google.com/ som henviseren.
- Gentag dette for alle nyhedswebsteder, du vil have adgang til (nogle fungerer muligvis ikke, selvom du foretager ændringerne, så husk det).
- Når du er færdig, skal du lukke konfigurationsvinduet.
- Tryk på Alt-tasten igen, og vælg Værktøjer> Standardbrugeragent> Rediger brugeragenter fra menuen.
- Vælg Ny> Brugeragent, og erstat strengen i feltet Brugeragent med Mozilla / 5.0 (kompatibel; Googlebot / 2.1; + // www.google.com/bot.html). Navngiv det Googlebot.
- Gå ud af menuen.
- Før du åbner disse sider, skal du trykke på Alt og vælge Standardbrugeragent> Googlebot.
Det er alt, hvad der er dertil. Det er lidt uheldig, at der ikke er nogen udvidelse til Firefox, der automatisk ændrer brugeragenten baseret på de websteder, du besøger.
Google Chrome
Google Chrome-brugere kan installere udvidelser som User Agent Switcher og Referer Control, som er tilgængelige for browseren til at gøre det samme.
Der er dog en anden mulighed, og det er at oprette en brugerdefineret udvidelse, der automatiserer processen i browseren.
Instruktioner findes på Elaineou. Alt hvad det kræver, er dybest set at oprette et nyt bibliotek på den lokale computer, oprette de to filer background.js og manifest.json deri, og kopiere og indsætte koden, der findes på webstedet, i filerne.
Du skal aktivere "udviklertilstand" på chrome: // extensions /, og kan derefter vælge "indlæse udpakket udvidelse" for at vælge den mappe, du har oprettet, de to filer i for at indlæse udvidelsen i Chrome.
Du kan ændre listen over sider, den understøtter for at tilføje nye.